from torch.utils.data import IterableDataset
import numpy as np
import os
#Just a Pytorch IterableDataset yielding (image,label,image_path) or whateverelse you want!
class DALIDataset(IterableDataset):
def __init__(self, base_path=None, **kwargs):
super().__init__()
self.files = os.scandir(base_path)
def __iter__(self):
for fil in self.files:
if fil.name.endswith("jpeg"): #or other supported types
image_path = fil.path
f = open(image_path, "rb")
image = np.frombuffer(f.read(), dtype=np.uint8) # don't decode the image just read the bytes!
label = np.array([1]) # some label
image_path = [ord(x) for x in image_path] #this is a hacky trick used to pass image_paths(strings) through DALI.
image_path = np.array(image_path, dtype=np.int32)
yield image, label, image_pathAre you still using PIL / openCV to open your images? :fearful:
Still doing torchvision transforms on CPU? :scream:
So what?
Image processing is critical for training a good CV model but if you are using the default torchvision & PIL combo to open and manipulate (resize,augment) your images you are doing it on the CPU. Surely more efficient backends besides PIL are available, and you can even build some of these libraries from source to enable faster implementations [1]
…OR you can just use the much faster NVIDIA DALI~
Note
Just as I was writing this post Torchvision 0.8.0 released native IO and support for GPU transforms. Comparisons & benchmarks down below… Spoilers: DALI is still faster!
What is DALI?
Nvidia DALI (Data Loading Library) is an extension/successor of the old NVVL (NVIDIA Video Loader) library.
Tell me more… why should I care about DALI?
In your dataloader it is not enough to just read the image bytes from disk (IO bound), you also have to decode the images based on the encoding (JPEG, PNG, TIFF…). This is where DALI shines 🤩 by using the CUDA accelerated NVJpeg library for decoding images. You can expect x2 or more speed-up based on your batch/image sizes.
Still not convinced? Check out these blogposts by Nvidia that explain & benchmark nvJPEG decoding in more detail [1] [2]. The new NVIDIA A100 GPUs even have a hardware JPEG decoder to further improve performance :fire: 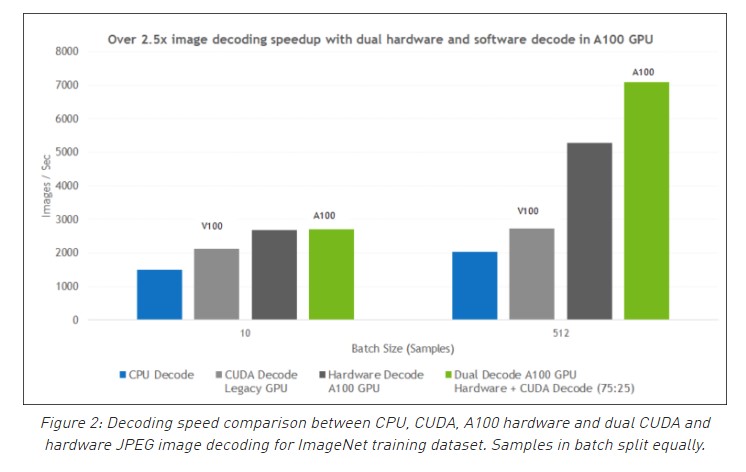
Note
I will update this post with my own benchmarks as soon as I can get my hands on an A100 ( つ ◕_◕ )つ
Of course you might argue that processing your images on the GPU means you will have less memory for your model [1] :thinking: But nowadays with larger and larger GPUs you can afford it! Besides the nvJPEG decoder only takes about 200mb~1gb depending on image/batch size [1][2] and the speed-up is well worth it! It is more likely that the bottleneck of your model is making CPU<->GPU copies and a starved input pipeline. Take a look at this case study on Resnet [1]
Highlights
- GPU accelerated JPEG decoding
- Built in prefetching (making you less IO bound)
- Image processing ops (resize,crop etc) on the GPU
Trust me you want to keep reading & use DALI. Why else would I go as far to changing all my dataloaders to DALI based ones and even write a blog post about it!
Requirements
This tutorial is focused on using DALI in Pytorch. But DALI also supports MXNet, Tensorflow & PaddlePaddle.
I will focus on image processing. Notably, DALI also supports processing other types of data such as audio and video. If what you are looking for involves text-preprocessing like tokenization etc. I suggest you check out NVIDIA RAPIDS cuDF instead[1][2][3]
ATTOW current DALI version:0.27 (I have been using DALI since 0.19)
Anatomy of a DALI Dataloading Pipeline
You start by defining a pipeline. The pipeline is where you define your operators (ops). DALI works by first creating a data processing graph defined by the define_graph function and then at execution time the data flows through (has an old tensorflowy feel to it).
To keep things visual;

If I had to map DALI to a torchvision likeness;
- pipeline -> torchvision.transforms.Compose (But instead of running things linearly like in Compose, you specify input->operation relations in
define_graph) - ops -> the rest of the torchvision.transforms
The below code is a simple but comprehensive example showing how a full dataloading pipeline works; returning images,labels & image_paths.
- It uses the
ExternalSourceop which is very flexible to modify to your use case. - Includes a trick to pass the image paths.
- Uses a Pytorch IterableDataset.
Tip
You can use DALI pipelines as a drop-in replacement for Pytorch Dataloader.
The Dataset
The Pipeline
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.types as types
#Using ExternalSource
class SimplePipeline(Pipeline):
#Define the operations in the pipeline
def __init__(self, external_datasource, batch_size=16, num_threads=2, device_id=0, resolution=256, crop=224, is_train=True):
super(SimplePipeline, self).__init__(batch_size, num_threads, device_id, seed=12)
# Define Input nodes
self.jpegs = ops.ExternalSource()
self.in_labels = ops.ExternalSource()
self.in_paths = ops.ExternalSource()
## Or pass source straight to ExternalSource this way you won't have do iter_setup.
# self.jpegs,self.labels,self.paths=ops.ExternalSource(source=self.make_batch, num_outputs=3)
# Define ops
self.decode = ops.ImageDecoder(device="mixed", output_type=types.RGB)
self.res = ops.Resize(device="gpu", resize_x=resolution,resize_y=resolution)
self.normalize= ops.CropMirrorNormalize(device="gpu",
dtype=types.FLOAT,
output_layout=types.NCHW,
crop=(crop, crop),
mean=[0.485 * 255,0.456 * 255,0.406 * 255],
std=[0.229 * 255,0.224 * 255,0.225 * 255])
self.path_pad=ops.Pad(fill_value=ord("?"),axes = (0,)) # We need to pad image_paths because we need the shapes to match.need dense tensor
self.iterator = iter(external_datasource)
# The external source should be fed batches
# I prefer to batch-ify things here because it keeps things compatible with an IterableDataset
def make_batch(self):
imgs = []
labels = []
paths = []
for _ in range(self.batch_size):
i,l,p=next(self.iterator)
imgs.append(i)
labels.append(l)
paths.append(p)
return (imgs,labels, paths)
# How the operations in the pipeline are used
# Connect your input nodes to your ops
def define_graph(self):
self.images = self.jpegs()
self.labels = self.in_labels()
self.paths = self.in_paths()
images = self.decode(self.images)
images = self.res(images)
images = self.normalize(images)
paths = self.path_pad(self.paths)
return (images, self.labels, paths)
# Only needed when using ExternalSource
# Connect the dataset outputs to external Sources
def iter_setup(self):
(images,labels,paths) = self.make_batch()
self.feed_input(self.images, images)
self.feed_input(self.labels, labels)
self.feed_input(self.paths, paths)The Dataloader
from nvidia.dali.plugin.pytorch import DALIGenericIterator
def make_pipeline(dataset, args, device_index=0, return_keys=["images","labels","image_path"], num_threads=2, is_train=True):
pipeline = SimplePipeline(dataset, batch_size=args["batch_size"], num_threads=num_threads,
device_id=device_index, resolution=args["resolution"], crop=args["crop"], is_train=is_train)
pipeline_iterator = DALIGenericIterator(pipeline, return_keys)
return pipeline_iterator
args = {
"resolution": 256,
"crop":224,
"batch_size": 128,
"image_folder": "/mnt/data/dali_test/" # Change this
}
dataset = DALIDataset(base_path=args["image_folder"])
train_dataloader=make_pipeline(dataset,args)
for batch in train_dataloader:
print(batch[0]["images"].shape,batch[0]["labels"].shape,batch[0]["image_path"].shape)
print(batch[0]["images"].device,batch[0]["labels"].device,batch[0]["image_path"].device)
# It is always batch[0]
# The dictionary keys are named by return_keys arg. The key operators
Okay that was a lot of code! :sweat_smile: And there are a lot of ops that can be used in a pipeline 1. Fear not :innocent: I categorize and list some of the most useful ones for image processing below.
Some of the operators have combined-shorthand operators for convenience, while some (marked *) are more efficient implementations of that combination.
Image ops
Color manipulation:
Brightness, Contrast, Hsv, Hue, Saturation - Combined ops: BrightnessContrast, ColorTwist(hue, saturation, brightness), ColorSpaceConversion(RGB,BGR,GRAY,YCbCr)
More ops 2:
Resize, Crop, Erase, Copy, Paste, Rotate, Flip, Jitter, Sphere, WarpAffine, Water, PeekImageShape - Combined ops: CropMirrorNormalize, RandomResizedCrop, ResizeCropMirror, FastResizeCropMirror*
Working with bounding boxes:
BbFlip, BBoxPaste, BoxEncoder, RandomBBoxCrop, SSDRandomCrop
General ops
Copy, Paste, Cast, Normalize, Pad, ElementExtract, Reinterpret, Reshape, Shapes, Slice, Transpose
Misc ops:
CoordTransform, CoordFlip, GaussianBlur, LookupTable, CoinFlip, NormalDistribution, Uniform
Custom ops: Allow you to define custom operations (more info below)
DLTensorPythonFunction, PythonFunction, TorchPythonFunction
Readers:
Other than the ExternalSource we have seen in the example above. There are a lot of readers for standardized types of datasets. - COCOReader, SequenceReader, VideoReader, FileReader, CaffeReader, MXNetReader, TFRecordReader.
I won’t talk about these because I haven’t used them. Also I prefer the more flexible ExternalSource operator.
Decoders
:star: ImageDecoder is the magic op doing nvJPEG decoding!
There are also combined ops: ImageDecoderCrop, ImageDecoderRandomCrop, ImageDecoderSlice. These don’t use hardware accelerated image decoding so I wouldn’t recommend.
Supported image types for decoding
JPEG (GPU decoding), PNG (fallback to CPU), TIFF (fallback to CPU), BMP (fallback to CPU), JPEG 2000 (GPU acceleration only available for CUDA 11), PNM, PPM, PGM, PBM.
Custom operator example
For operations not currently available you can create your own implementation in Python. Let me preface this by saying this makes the whole pipeline a lot less efficient and should be only used if you are desperate [1] OR confident in C++ [2] (which doesn’t have the same handicap)
An example;
GIF hack
GIF image decoding is currently not supported so if we have gif images we can use ops.PythonFunction and define our own decoder using PIL.
# replace self.decode in SimplePipeline with the below also passing arguments exec_async=False,exec_pipelined=False
# if the ops device is gpu, it expects inputs&outputs to be gpu
self.decode = ops.PythonFunction(function=self.get_frame_from_gif_py, num_outputs=1, device='gpu')
from io import BytesIO
from PIL import Image
import cupy as cp # We use cupy to pass inputs in GPU. You can just use device="cpu" and numpy
def get_frame_from_gif_py(self,img_array):
#not efficient
im = Image.open(BytesIO(cp.asnumpy(img_array)))
im.seek(0)
im=im.convert('RGB')
o=cp.asarray(im)
return o
# We don't use gpu decoding but at least the rest of our augmentations can be done on GPUPitfalls
String type inputs are not supported afaik [1], although there is a workaround we have used above for passing image_paths.
Another common source of exception is that;
One bad apple can throw your whole pipeline away!
DALI works by building a data processing graph and running it at execution time with some efficient threaded magic behind the python scenes 1. So if there is a corrupted image an exception is thrown and you whole pipeline goes :skull:
:star2: But there is a solution~ You can check your images beforehand for corrupted images using the image-checker library/tool I have made specifically for this purpose. Even if you are not using DALI for your ML pipeline you can check for corrupted images using this DALI powered tool. Chances are you have a couple (hundred,thousand…) broken images clogging your pipeline, especially if using images scraped from the web. It is as easy as pip3 install image-checker
image-checker --path ./my_folder_of_images --recursive
Torchvision vs DALI
While I was preparing this blogpost torchvision v0.8 came out :hear_no_evil: with; torchscript, batch and GPU support for transforms & native image IO operations read_image ,decode_image (jpeg,png only). 3
What I was going to post prior to 0.8 :joy:: There is interest in GPU based torchvision transforms [1][2][3]. But at the moment it seems to go nowhere.
Now I will compare the above DALI pipeline with a torchvision equivalent. Namely, using torchvision.io.decode_image and batch transforms on the GPU. The code is below (click show code)
Code
import os
import numpy as np
import torch
import torchvision.transforms as T
from torch.utils.data import DataLoader, IterableDataset
from torchvision.io import decode_image, read_image
#Just a Pytorch IterableDataset yielding (image,label,image_path) or whateverelse you want!
class DALIDataset(IterableDataset):
def __init__(self, base_path=None, **kwargs):
super().__init__()
self.files = os.scandir(base_path)
self.resize=T.Resize([256,256])
def __iter__(self):
for fil in self.files:
if fil.name.endswith("jpeg"): # or other supported types
image_path = fil.path
f = open(image_path, "rb")
image = np.frombuffer(f.read(), dtype=np.uint8) # don't decode the image just read the bytes!
label = np.array([1]) # some label
# Can only decode one image at a time (decode_image doesnt support batch)
image=torch.from_numpy(image)
image=decode_image(image)
#Have to resize here for matching sizes for batch
image=self.resize(image)
yield image, label, image_path
args = {
"resolution": 256,
"crop":224,
"batch_size": 128,
"image_folder": "/mnt/data/dali_test/"
}
transforms = torch.nn.Sequential(
T.CenterCrop(args["crop"]),
T.ConvertImageDtype(torch.float),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
)
dataset = DALIDataset(base_path=args["image_folder"])
train_dataloader = DataLoader(dataset,batch_size=args["batch_size"], shuffle=False, num_workers=2)
for images,labels,image_paths in train_dataloader:
# print(images.shape)
images=images.to("cuda:0")
images=transforms(images)
# print(images.shape,images.device)
breakBenchmarking the torchvision vs DALI dataloader codes above, with different batch sizes…And the 🏆 goes to DALI which was consistenly ~2.5 faster than torchvision. Although I wasn’t able to find a lot of info on these new torchvision functionalities. I can attribute this difference to a couple of things:
torchvision.io.decode_imagedecodes one image at a time.decodes on the CPU
Edit: nvjpeg might be coming soon to torchvision! > twitter: https://twitter.com/nairbv/status/1326873995887710208
moving decoded image to gpu takes longer than if encoded image bytes were moved to gpu.
I also haven’t seen much speed-up between CPU vs GPU transforms on the tested ops :thinking:
Although I wish DALI becomes the defacto standard of dataloading, I still feel torchvision’s move towards native tensor based (& torchscriptable) transforms is a good (long awaited) one.
The future
NVIDIA has been pushing the everything on the GPU agenda for a while.
Not to mention the popularization of awesome RAPIDs & BlazingSQL libraries. Did you like all of these? Then stay exited because I bet NVIDIA has more in store :wink: with NVIDIA RTX IO: GPU Accelerated Storage. It looks like in the future going from storage straight to GPU will be even faster :runner::leopard:

Q&A
Thanks to @JanuszL from NVIDIA for being the fastest replier to any issues/questions I had with DALI.
If there is an error please let me know~ Questions & Contributions & Comments are welcome~
Note
There will be a Part-2 post soon about Kornia that focus on augmentations on the GPU, making it the perfect companion with DALI.
Follow me on Twitter to be notified of new posts~
Footnotes
Not sure what some of these ops mean, check out the official augmentation gallery examples.↩︎
Full table of DALI ops showing GPU & input type support is here.↩︎
For more details I refer you to the official example notebook↩︎